Kafka 등장배경

데이터를 전송 - Kafka Producer(source application) 데이터를 받음 - Kafka Consumer(targer application)
- 기존 단방향 통신에서 producer와 consumer가 많아져 데이터 라인이 복잡해졌다.
- 따라서 배포와 장애애 대응이 어려워졌고
- 프로토콜 포맷의 파편화(일한 코드로 작성된 웹페이지 또는 웹 앱임에도 불구하고 브라우저에 따라 서로 다른 화면이나 동작결과를 발생시키는 것)가 심해졌다.
따라서 sa와 ta의 커플링(연관성?)을 약하게 하기 위해 등장
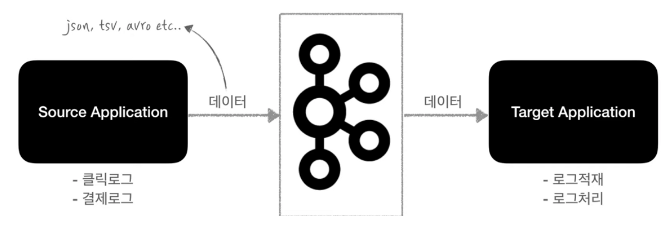
producer -> kafka -> consumer 로 데이터를 주고받음
kafka : 일종의 큐
데이터를 넣는 역할 : producer 데이터를 받는 역할 : consumer
Kakfa의 장점
- 고가용성 : 서버 이슈 등에 대해 데이터 복구과 쉬움
- 낮은 지연
- 높은 처리량
Kafka 토픽(feat 파티션)
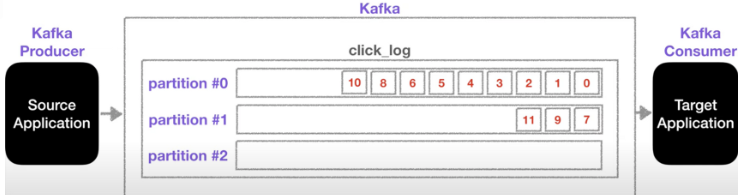
- 카프카에 데이터가 들어갈 수 있는 공간
- 여러개 생성이 가능
- 이름이 명확할 수록 좋음
- 하나의 토픽은 여러개의 파티션으로 구성
- 첫번째 파티션 번호는 0번부터 하나의 파티션에 데이터가 큐와 같이 차곡차곡 쌓인다.
- 오래된 데이터 부터 consumer가 가져가고 데이터가 더 들어오지 않으면 대기(데이터는 그대로 남아있다.)
- 따라서 새로운 consumer가 붙는다면 데이터가 남아있어 사용할 수 있다. (consumer 그룹이 다름, auto.offset.reset = earliest 일 경우) 따라서 동일 데이터에 대해서 두번 처리가 가능하다.
- 분석하고 시각화 하기 위에 엘라스틱 서치에 저장, 백업을 위해 하둡에 저장을 하기도 한다.
- 파티션이 여러개 일때 데이터를 보낼때 key를 지정하여 파티션으로 보낸다. (키가 null이고 기본 파티셔너일 경우 round robin(할댱량에 따라 배분)으로 데이터가 파티션에 들어간다.)
- 파티션을 늘리면 컨슈머 갯수를 늘려 데이터 처리를 분산시킬 수 있다.(단 파티션은 삭제하지 못하며 레코드가 저장되는 최대 시간과 크기를 지정할 수 있는데 이럴 통해 일정한 기간, 용량동안 데이터를 저장 가능, log.retention.ms : 최대 record 보존 시간, log.retention.byte : 최대 record 보존 크기(byte))
Kafka 프로듀서

데이터를 kafka 토픽에 생성 (대량, 실시간 적재 가능)
- Topic에 해당하는 메시지를 생성
- 특정 Topic으로 데이터를 publish
- 처리 실패 시 재시도
public class Producer {
public static void main(String[] args) throws IOException {
//프로듀서를 위한 설정
Properties configs = new Properties();
//부트 스트랩 서버 설정을 로컬 호스트의 카프카를 바라보도록 설정 (되도록 2개 이상의 ip와 port를 설정)
configs.put("bootstrap.servers", "localhost:9092");
//직렬화, key : 메시지를 보내면 토픽의 파티션이 지정될 때 쓰임
configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//설정한 프로퍼티로 카프카 프로듀서 인스턴스 생성
KafkaProducer <String, String> producer = new KafkaProducer <String,String> (configs);
//어느 토픽에 넣을것인지 어떤 key와 value를 담을 것인지 설정 (여기선 key 1, click_log토픽에 login
value 전달)
ProducerRecord record = new ProducerRecord <String,String>("click_log", "1", "login");
producer.send(record); //데이터 전송
producer.close()
Broker, Replication, ISR

Broker
- kafka가 설치 되어 있는 서버 단위(보통 3개 이상의 브로커로 구성하여 사용 권장)
- 만약 파티션 1개, replication 1, broker 3대 라면 3대중 1대에 해당 토픽 정보를 저장
Replication
- 파티션의 복제를 뜻함
- replication이 1이면 파티션은 1개 3이면 원본1개, 복제본 2개로 구성
- broker 개수를 replication이 초과할 수 없다.
- 원본 파티션 : 리더 파티션, 복제된 파티션 : 팔로워 파티션
- 갑자기 하나의 브로커가 사용불가능 하게 되었을 때 복제본 이 다른 브로커에 존재하여 복구가 가능하다. (리더를 승계)
- ack 0,1 all 옵션 3개중 한개를 골라서 사용 0일 경우 리더 파티션에 데이터를 전송, 응답값을 받지 않음 (속도는 빠르나 완료 결과, 나머지 파티션에 복제 되었는지는 모름) 1일 경우 응답값을 받음(나머지 파티션에 복제 되었는지는 모름) all 모두 응답값을 받음(속도가 현저히 느림)
- 브로커의 리소스양도 늘어나 retention date, 저장시간을 잘 신경써서 정하는게 좋음
(3개 이상의 브로커를 사용할때 replication은 3을 추천)
ISR(In Sync Replica) 리더 파티션 + 팔로워 파티션
Kafka Consumer
토픽의 데이터를 가져온다.(폴링)

- 토픽의 파티션으로부터 데이터를 polling
- Partition offset 위치 기록(commit)
- Consumer가 여러개일 경우 병렬처리(더욱 빠른속도로 데이터 처리)
offset
- 파티션에 들어간 데이터가 가지는 고유 번호
- 토픽별로, 파티션별로 별개로 지정
- 컨슈머가 데이터를 어느정도 지점까지 읽었는지 확인하는 역할
- 컨슈머가 데이터를 읽으면 offset을 commit → consumer_offset 토픽에 저장됨
- 만약 사고로 정지가 되어도 consumer_offset을 통해 중지 되었던 시점을 알고 있어 재시작 가능
- cosumer_offset 토픽은 cosumer 그룹별, 토픽별 나누어 저장한다.
public class Consumer {
public static void main(String[] args) {
//java Properties를 통해 cosumer 옵션 지정
Properties configs = new Properties();
configs.put("bootstrap.servers" , "localhost:9092); //kafka broker 설정
configs.put("group.id" , "click_log_group); //consumer group 지정
//key, value에 대한 직렬화 설정
`configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");`
`configs.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");`
//consumer 인스턴스 생성
`KafKaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs);`
//어느 토픽에서 데이터를 가져올지를 설정 (특정 토픽의 일부 파티션의 데이터만 가져오고 싶을 경우 assign() 매서드 사용
`consumer.subscribe(Arrays.asList("click_log"));`
`while(true){`
//0.5초 동안 데이터가 도착하기 기다림 (0.5초동안 봤는데 없으면 빈값의 records 변수를 반환)
//records 변수 : 데이터 배치로서 레코드의 묶음 list kafka에서 데이터를 처리할때 record로 나누어 처리
`ConsumerRecords<String, String> records = consumer.poll(500);`
`for(ConsumerRecord<String, String> record : records) {`
`System.out.println(record.value());` //record.value() producer 가 전송한 데이터
//데이터를 하둡 또는 엘라스틱 서치에 담을 수 있다.}}}}
Kafka 설치 및 테스트
brew install kafka → brew services start zookeeper → brew services start kafka brew info kafka (kafka가 설치되어 있는 위치에서 bin파일로 접근) ( 예 : cd /usr/local/Cellar/kafka/3.0.0/bin
토픽 생성 예시 (bin에서) ./kafka-topics —create —zookeeper localhost:2181 —replication-factor 1 -partitions 1 —topic topicname1
토픽에 데이터 삽입 ./kafka-console-producer —broker-list localhost:9092 —topic topicname1 스크립트를 실행시키면 string 전송 가능
전달된 데이터 조회 ./kafka-console-consumer —bootstrap-server localhost:9092 —topic devwonyoung —from-beginning
Kafka lag
- Consumer lag : producer가 데이터를 넣는 속도와 consumer가 가져가는 속도가 달라 offset이 서로 달라짐 (예 5번을 넣었는데 3번을 아직 꺼내는중)
- lag은 파티션 갯수만큼 생성될 수 있다.
- 이 중 높은 숫자의 lag을 records-lag-max 라고 부른다.
Burrow 컨슈머 lag을 모니터링 하기위한 아파치 카프카 외부 오픈 소스 (Burrow를 사용하지 않고 모니터링 한다고 하면 influxdb나 elasticsearch와 같은 db에 넣은 뒤 grafana 같은 대쉬보드를 활용해야 하는데 컨슈머 로직 단에서 lag을 수집하면 컨슈머가 비정상 종료시 lag 정보를 보낼 수 없고 따로 개발해줘야 하는 수고가 있다.
- 멀티 카프가 클러스터 지원(클러스터가 여러개여도 burrow 하나로 모든 컨슈머의 lag을 모니터링 할 수 있다.
- sliding window를 통한 consumer의 status 확인 (error, warning, ok) 예시) warning : 데이터양이 일시적으로 많아지면서 consumer offset이 증가되고 있다. error : 데이터양이 많아지고 있는데 consumer가 데이터를 가져가지 않는다.
- Http api 제공 하여 response data를 통해 여러가지를 활용 가능하다.
Kafka Streams

- 데이터를 변환하기 위한 목적으로 사용하는 API
- 스트림 프로세싱을 지원하기 위한 다양한 기능 제공
- Stateful 도는 Stateless 와 같이 상태기반 스트림 처리 가능
- Stream api와 DSL(Domain Specific Language)를 동시 지원
- Exactly-once 처리, 고 가용성 특징
- Kafka security(acl, sasl 등) 완벽 지원
- 스트링 처리를 위한 별도 클러스터(yarn 등) 불필요
Kafka Connect

- 많은 경우 Kafka client로 Kafka로 데이터를 넣는 코드를 작성할때도 있지만, Kafka connect를 통해 data를 Import/Export 할 수 있음.
- 코드 없이 configuration으로 데이터를 이동시키는 것이 목적
- Standalone mode, distribution mde 지원
- Rest api interface를 통해 제어
- Stream 또는 Batch 형태로 데이터 전송 가능
- 커스텀 connection을 통한 다양한 plugin 제공(File, S3, Hive, Mysql etc....)
Kafka Mirror maker

- 특정 카프카 클러스터에서 다른 카프카 클러스터로 Topic 및 Record를 복제 하는 Standalone tool
- 클러스터간 토픽에 대한 모든 것을 복제하는 것이 목적
- 신규 토픽, 파티션 감지기능 및 토픽 설정 자동 Sync 기능
- 양방향 클러스터 토픽 복제
- 미러링 모니터링을 위한 다양한 metric(latency, count 등) 제공
Kafka 생태계를 지탱하는 application들
- confluent/ksqlDB : sql구문을 통한 stream data processing 지원
- confluent/Schema Registry : avro기반의 스키마 저장소
- confluent/REST Proxy : REST api를 통한 consumer/producer
- linkedin/Kafka burrow : consumer lag 수집 및 분석
- yahoo / CMAK : 카프카 클러스터 매니저
- uber/uReplicator : 카프카 클러스터 간 토픽 복제(전달)
- Spark stream : 다양한 소스(카프카 포함)로 부터 실시간 데이터 처리
Kafka Partitioner

프로듀서가 데이터를 보내면 파티셔너를 통해서 브로커로 데이터가 전송된다.
레코드에 포함된 메시지 키 또는 메시지 값에 따라서 데이터를 토픽에서 어떤 파티션에 넣을지 결정하는 역할을 한다.
default 설정 : UniformStickyPartitioner
커스텀 파티셔너로 특별한 타피셔너를 만들 수 있다. (에: VIP 일 경우 데이터 처리속도를 더 빠르게..)
참고
https://blog.voidmainvoid.net/179
'devops' 카테고리의 다른 글
| WebFlux, Reactive Stream (0) | 2023.08.10 |
|---|
