동기

- Thread1이 작업을 시작 시키고, Task1이 끝날때까지 기다렸다 Task2를 시작한다.
- 따라서 함수를 호출한 곳에서 응답을 받는 것 호출과 응답이 동시에 이루어 진다.
- 설계가 간단하고 직관적이나 결과가 주어질 때까지 아무것도 하지 못한다.
비동기
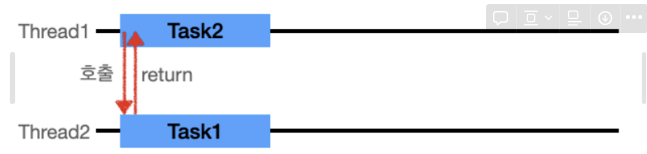
- Thread1이 작업을 시작 시키고, 완료를 기다리지 않고, Thread1은 다른 일을 처리할 수 있다.
- 따라서 호출시점과 응답시점이 같지 않다
- 즉 동기 비동기는 호출되는 함수의 작업 완료 여부가 관심사
- 구현이 복잡하나 그 시간동안 다른 작업을 할 수 있으므로 효율적이다.
Blocking
- 함수를 call 했을 때 메소드의 return을 받을때 까지 Thread 가 멈춰있는 상태를 의미
- 예를들어 우리가 fn hello()라는 함수를 만들었다고 가정했을 때 hello()라고 함수를 호출하면 함수의 return이 있고나서 함수가 종료되고 다음줄에 i++; 같은 코드를 실행하는 것이다.
Non-blocking
- Non-blocking은 함수를 call 했을 때 메소드의 return 오기 전에 다음줄을 실행하는 상태를 말한다.
- 이것 또한 예를들면 hello()를 호출했어도 return이 되기 전에 다음줄의 i++; 같은 코드가 실행될 수 있는 상태를 의미하는 것이다.
- 즉 호출되는 함수가 제어 관심사
- call back 을 파라미터로 넘겨준다. return 후 제어권을 넘겨주는데 처리 후 call back을 통해 반환
동기/비동기, blocking/non-blocking 조합

blocking + Synchronous
결과가 처리되어 나올때까지 기다렸다가 return 값으로 결과를 전달한다.
non-blocking + Asynchronous
작업 요청을 받아서 별도의 프로세서에서 진행하게 하고 바로 return(작업 끝)한다.
결과는 별도의 작업 후 간접적으로 전달(callback)한다.
MVC Pattern

Model, View, Controller의 약자.
장점
- 비즈니스 로직과 UI를 분리하여 유지보수를 용이하게 해주는 장점이 있다.
단점
- 한 Model은 다수의 View들을 가질 수 있고 반대로 Controller를 통해서 한 View에 연결되는 Model도 여러 개가 될 수 있다.
- 이렇게 되면 결과적으로 View와 Model이 서로 의존성을 띄게 되고 프로그램 특성상 필연적으로 화면에 복잡한 화면과 데이터의 구성 필요한 구성이라면, Controller에 다수의 Model과 View가 복잡하게 연결되어 있는 상황이 생길 수 있다.
- 또한 사용자의 요청이 들어왔을 때 그 때마다 Thread를 생성하여 처리하는데 리소스가 낭비되며 Thread Pool Hell이 발생 할 수 있다. (동기 + 블로킹 방식이기 떄문에)
- Thread Pool Hell : Thread 생성 비용은 크기 때문에 미리 생성하여 재사용함으로써 효율적으로 사용한다. 서버 성능에 맞게 Thread 최대 수치를 제한 시키는데, tomcat 기본 사이즈는 200 thread pool size를 지속적으로 초과하게 된다면, Queue에서 계속 대기하게 된다. 전체 대기시간이 늘어나게 되는데 이런 현상을 Thread Pool Hell 이라 한다.
Model : Controller에서 다루는 데이터들의 정의. DTO, DAO와 같은 아이들.
View : Controller에서 전달 받은 데이터 등을 이용하여 client가 보는 화면을 만드는 부분. css, html같은 파일들.
Controller : 비즈니스 로직 등을 처리하는 영역. Model과 View를 연결시켜주는 역할을 하며 프로그램의 동작순서나 방식을 제어한다. (여기에 더불어 controller layer (비즈니스 영역) , service layer(로직)을 분리하는 구현하는 경우가 많다.)
Spring 에서 Non-blocking I/O를 이용해서 이런점들을 해결하고 효율적으로 작업을 처리할 수 있는 방법을 제공한다. 그 수단이 WebFlux이다.
WebFlux
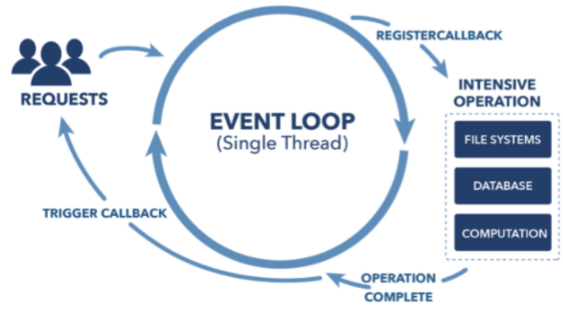
Spring WebFlux의 경우에는 계속 이슈가 되고 있는 Event driven 방식이고 비동기 논블로킹 방식이다.
(Event driven : 프로그램이 어떤 유저액션(이벤트)에 대한 반응으로 동작하는 패턴, //비슷한말 아닌가? ...
다수의 사용자가 이벤트를 발생시키고, 이러한 결과는 또 다른 사용자 혹은 시스템을 실시간으로 변경을 발생시킨다.)
사용자들에 의해 요청이 들어온다 → Event Loop를 통해서 작업이 처리가 된다. → 다수의 요청을 적은 Thread로도 커버할 수 있다. (Non Blocking이기 때문에)
Spring Webflux에서 사용하는 reactive library가 Reactor이고 Reactor가 Reactive Streams의 구현체이다. (즉 Webflux는 Reactive Stream 방식을 따른다?..)
그래서 Webflux 문서에 Reactive Streams가 언급되는 것이고 그거와 같이 Reactor가 나오고
이떄 등장하는 주요 객체가 Mono 와 Flux이다.
장점
- 그래서 이 방식의 경우 Spring MVC에 비해 사용자의 요청을 대량으로 받아낼 수 있다는 장점이 있다.
단점
- 요청을 처리하는 파이프라인의 요소들이 모두 논블로킹하게 동작해야만 의미가 있다.(당연히!)
- 따라서 어떤 특정한 구간에서 블로킹이 발생하는 구간이 있다면 거기서부터 Thread Pool Hell같은 문제들이 발생하는 것이다.
- Thread는 2개인데 Blocking이 걸리는 API를 열명 이서 동시에 호출한다면 결국엔 Spring MVC처럼 8명이 I/O 작업이 끝날 때까지 기다려야 하는 구조가 되어버리기 때문이다.
Mono
Mono는 0-1개의 결과만을 처리하기 위한 Reactor의 객체
Flux
Flux는 0-N개인 여러 개의 결과를 처리하는 객체
Reactor를 사용해 일련의 스트림을 코드로 작성하다 보면 보통 여러 스트림을 하나의 결과를 모아줄 때 Mono를 쓰고, 각각의 Mono를 합쳐서 여러 개의 값을 여러 개의 값을 처리하는 Flux로 표현할 수도 있습니다.
Reactive Stream이란
논블로킹과 백프레셔를 갖춘 비동기 스트림 처리를 위한 표준
Steaming

왼쪽의 전통적인 방식은 사용자 요청이 오면 해당 요청의 페이로드 데이터를 모두 메모리에 저장하고 데이터 베이스에서 조회한 데이터들도 메모리에 저장하며 마지막으로 응답을 위한 데이터 생성해서 메모리에 저장 후 사용자에게 응답을 보낸다. 한번의 요청에 대한 처리하기 위해 많은 데이터가 어플리케이션 메모리에 저장됩니다. 하나의 요청에서 처리하는 데이터가 많을 경우, 메모리가 부족할 가능성(out of memory의 가능성)이 있습니다. 하나의 요청에 데이터가 많지 않더라도 순간적으로 많은 요청이 몰리면 다량의 GC(Garbage Collection)이 발생할 가능성이 있습니다.
택배 → 창고에 물품 → 필요한 양만큼 가져간다. → 창고xxx Stream 은 발송을 하면 실시간으로 바로 퀵배송
이러한 문제를 해결하기위해 스트림 방식을 사용하면 크기가 작은 시스템 메모리로도 많은 양의 데이터를 처리할 수 있습니다. 즉, 최대한 지금 당장 처리할 데이터만 메모리에 저장되어 있기 때문입니다.
Push 방식(옵저버 패턴)
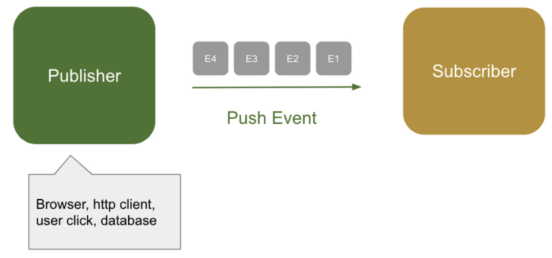
Publisher가 Event를 Comsume하는 Subscriber에게 이벤트를 보내는 방식을 Push 방식
Publisher가 초당 100개의 Event를 보낼 경우, Subscriber가 좀 더 느린 초당 10개의 이벤트를 처리한다면 Subscriber는 대기하는 이벤트를 위한 Queue를 두어야 한다. (한계가 있다. Out of Memory 에러 발생)
Pull 방식(리액티브 스트림 패턴)
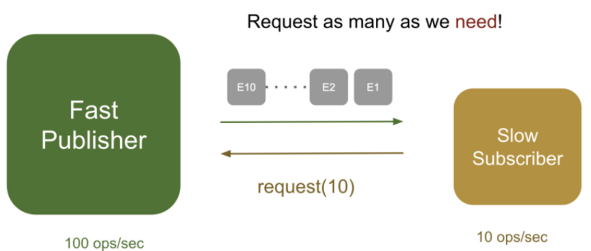
Pull 방식의 경우, Event를 처리하는 Subscriber가 반대로 자신이 처리할 사이즈의 Event를 Publisher에게 요청하는 방식을 말합니다. Publisher는 요청받은 만큼만 전달하면 되고, Subscriber는 더 이상 ‘Out of Memory’ 에러를 걱정하지 않아도 됩니다.
풀 방식에선 이렇게 전달되는 모든 데이터의 크기를 구독자가 결정합니다. 이런 다이나믹 풀 방식의 데이터 요청을 통해서 구독자가 수용할 수 있는 만큼만 데이터를 요청하는 방식이 백 프레셔입니다.
⚽ 참고
https://velog.io/@dyllis/Spring-MVC-vs-WebFlux
https://velog.io/@yebali/Spring-Boot-MVC
